Cell-type annotation#
Cell-type annotation is fundamental for data interpretation and a prerequisite for almost any downstream analysis. Performing cell-type annotation manually based on clustering is a widely-used and straightforward approach. To this end, previously known marker genes can be checked for their expression across clusters and cell-type labels assigned accordingly. Alternatively, as a more unbiased approach, it is possible to perform differential gene expression analysis between clusters, and assign cell-types based on cluster-specific differentially expressed (DE) genes. Panels of marker genes can be obtained from publications or cell-type databases such as CellMarker [103] or PanglaoDB [104].
1. Load the required libraries#
import pandas as pd
import scanpy as sc
2. Load input data#
adata = sc.read_h5ad("../../data/input_data_zenodo/atlas-integrated-annotated.h5ad")
markers = pd.read_csv("../../data/input_data_zenodo/cell_type_markers_lung.tsv", sep="\t")
markers
| cell_type | gene_symbol | |
|---|---|---|
| 0 | Alevolar cell type 1 | AGER |
| 1 | Alevolar cell type 1 | CLDN18 |
| 2 | Alevolar cell type 2 | SFTPC |
| 3 | Alevolar cell type 2 | SFTPB |
| 4 | Alevolar cell type 2 | SFTPA1 |
| ... | ... | ... |
| 84 | Vessel | PECAM1 |
| 85 | Endothelial cell lymphatic | VWF |
| 86 | Endothelial cell lymphatic | CCL21 |
| 87 | Neutrophils | CSF3R |
| 88 | Neutrophils | CXCR2 |
89 rows × 2 columns
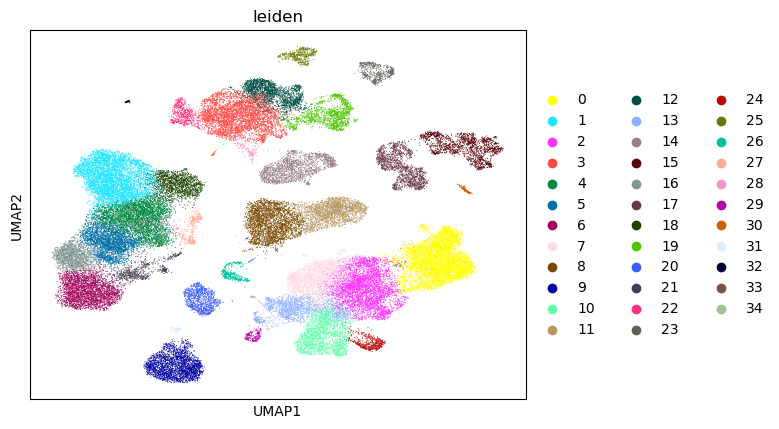
3. Perform unsupervised clustering using the leiden algorithm#
sc.tl.leiden(adata, resolution=1)
sc.pl.umap(adata, color="leiden")